Shutting newsbyside.com down
2023-03-05
After running newsbyside for the last year, I've decided to shut it down in the following days.
2 main reasons for shutting it down
Don't want to maintain the python scraper when it breaks.
Finding out that scraping endpoint x breaks the script is pretty annoying, and I don't have too much time for fixing that stuff.
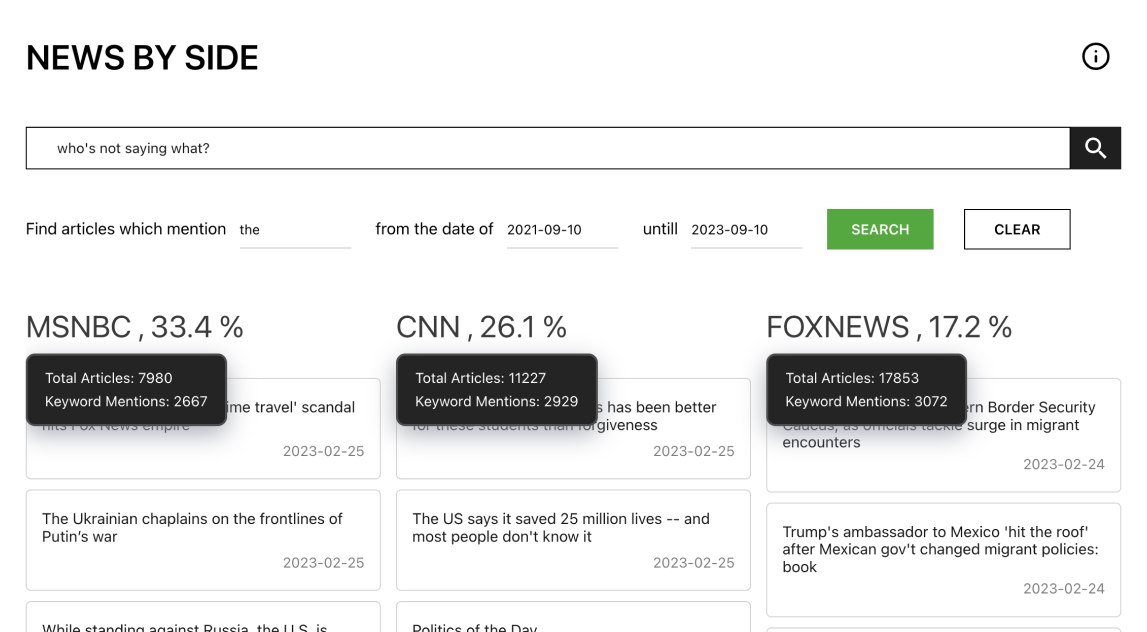
The difference between the scraped articles for each network is quite substantial